Este problema ha estado rondando por mi cabeza durante varios días y aún no le encuentro una solución que me satisfaga. Les cuento para que me den su opinión al respecto.
El otro día un usuario vino a mi preguntándome sobre un archivo en formato ASCII y mi mente viajó a los años 90’s. Hasta recordé una fotocopia con los códigos de los caracteres porque en aquellos días usábamos ciertos símbolos para construir cajas en los menús de nuestros programas (aullaron coyotes en el cerro).

Copia del Código ASCII
Le pedí que me mostrara los requisitos requeridos (la lista completa la pueden leer aquí: Inscripción en el RFC ). Hasta llegar al requisito en cuestión que es el número 4.

archivo en formato ascii
4. El formato del archivo debe ser en Código Estándar Americano para Intercambio de Información (ASCII).
¿Archivo de texto? ¡Obvio!
Aunque no lo menciona es claro que el archivo a entregar es un archivo de texto. Incluso los dos puntos anteriores nos dan una pista del contenido del archivo:
- Sin tabuladores.
- Únicamente mayúsculas.
Para generar un archivo de texto hay un montón de programas. Mis favoritos en Linux Sublime , Geany , Gedit , y en Windows el famoso Notepad++ , vamos que por editores no paramos.
Y con eso podemos generar el archivo, sin embargo ¿A que se refiere con eso de formato ASCII?.
¿Será la codificación del archivo?
A lo mejor el requisito se refiere a la codificación del archivo. Pero como pueden ver en la siguiente imagen hay un montón de opciones y ninguna de ellas es ASCII.
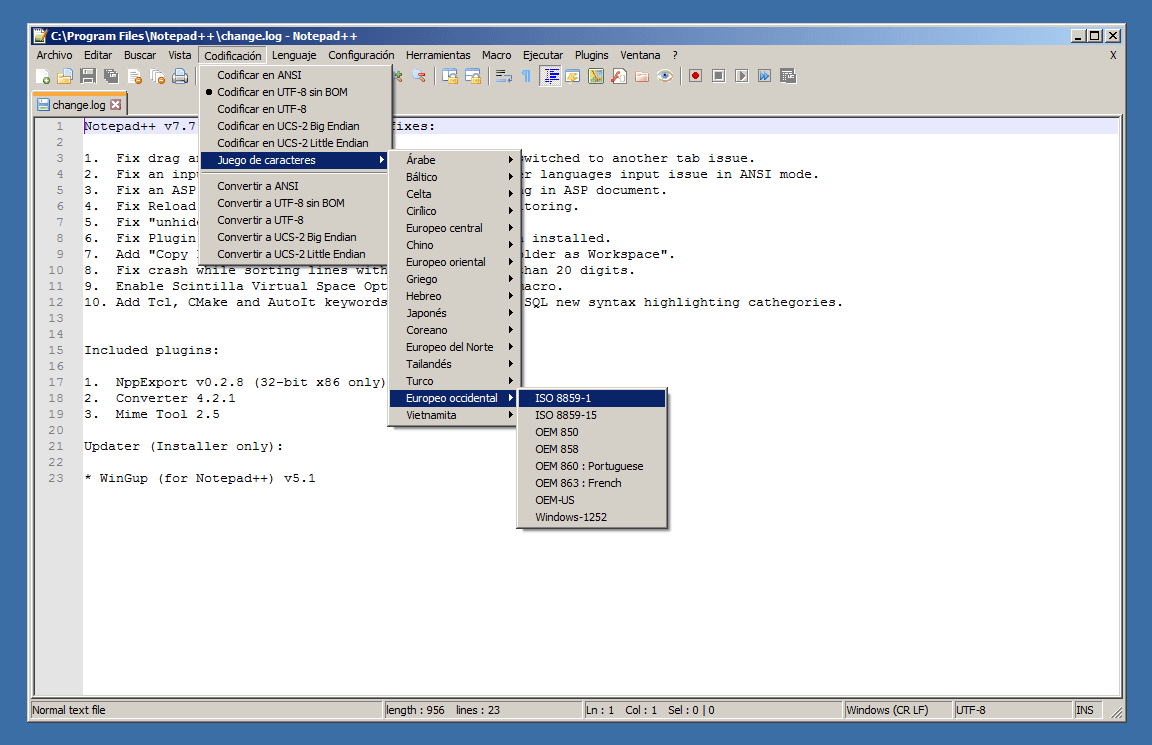
Notepad++ mostrando las opciones de codificación.
La codificación de los archivos es importante para que se interpreten apropiadamente los textos, por ejemplo léase: Los subtítulos muestran letras raras .
Quiero suponer que a lo mejor lo que quieren es que no aparezcan vocales acentuadas o la letra Ñ del español. Pero incluso esas limitantes del código ASCII original fueron resueltas mediante páginas de códigos .
Este es un caso más para el pingüino que investiga. Aunque para ser sincero creo que es un callejón sin salida.
Ustedes que opinan ¿Cúal es su mejor teoría? ¿Qué es lo que habrán querido decir con este requisito?.
Misterio resuelto.
Gracias al comentario de Traktek parece que se ha resuelto el misterio, al menos de manera no oficial.
Él menciona el comando file para saber el tipo del archivo. Bueno, pues utilizando la codificación UTF-8 hice un sencillo archivo de prueba.

Archivo de prueba ASCII
El comando file lo identifica como ASCII.
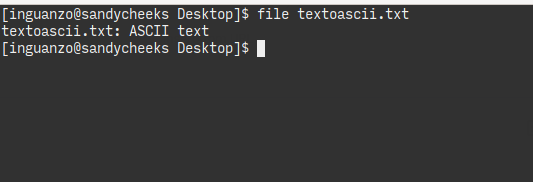
Y el resultado es que lo identifica como ASCII
Pero si al archivo le agrego una Ñ, la cosa cambia a UTF-8.

Archivo de prueba UTF8
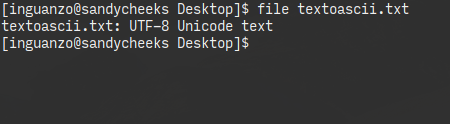
El resultado es que file lo identifica como UTF-8
Y con eso ya tiene algo de sustento la teoría de que el archivo no debe de incluir letras acentuadas o la letra Ñ.
¡Muchas gracias Traktek por tu comentario!.