
Me dio gusto ver que los libros de texto gratuitos están disponibles para su consulta en internet. En un principio creí que se podían descargar en formato PDF pero no existe esta opción.
Y luego me dije a mi mismo … Mi mismo ¿Y si descargas las páginas del libro y generas un PDF a partir de esas imágenes?
Así que puse manos a la obra y elaboré un programita en bash para descargar los libros de texto gratuitos o cualquier libro que se presente en un formato similar.
A descargar las imágenes del libro.
Lo primero es abrir un libro.
En este enlace están disponibles los libros de primaria:
Y en este otro los de secundaria:
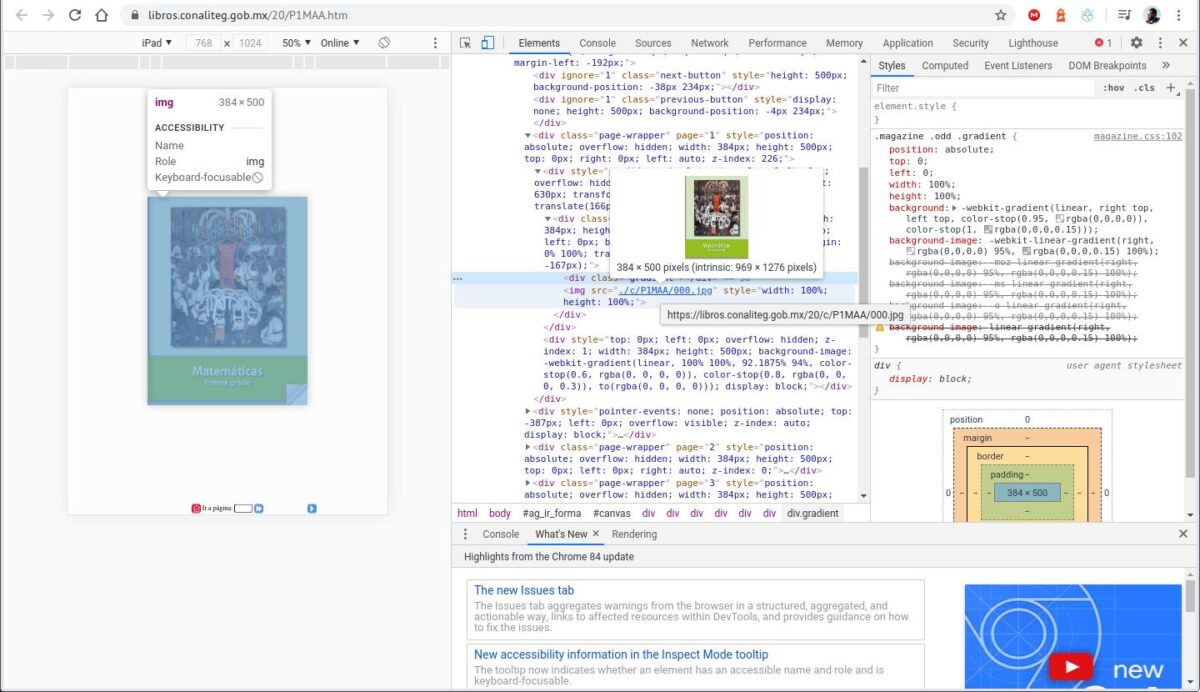
Inspección de la página donde se encuentra el libro para obtener la carpeta donde se almacenan las imágenes.
Para ejemplo práctico elegí el Libro de matemáticas de primer año . Si inspeccionamos la página del libro verán que las imágenes están almacenadas en la misma carpeta y las imágenes tienen como nombre un número de 3 dígitos de este modo.
https://libros.conaliteg.gob.mx/20/c/P1MAA/000.jpg
Así que es relativamente fácil hacer un script en Bash para que haga un barrido y con wget descargar una por una las páginas del libro.
#!/bin/bash
# Descargar libro de texto
for i in {000..300}
do
wget https://libros.conaliteg.gob.mx/20/c/P1MAA/$i.jpg
done
En realidad no se la cantidad de hojas disponibles, así que elegí un número alto. Cuando el script empiece a informar errores en las descargas sabré que ya no hay más hojas disponibles.
Descargando ando …
Ahora a encuadernar las hojas sueltas con un PDF
El archivo PDF nos va a servir para guardar todas las imágenes en un solo archivo. Esto no es algo nuevo para mí, ya había hecho algo similar en Convertir todas las imágenes de un directorio a PDF .
gm convert *.jpg -adjoin -compress JPEG libro.pdf
Si agregamos esta instrucción al final del script en bash, todo se hace en una sola ejecución. Para este ejemplo, el archivo resultante quedó en 49.7 MB ¡Excelente!

El resultado final, un pdf que contiene todas las imágenes del libro.
Enseñándole a leer al PDF.
Todo estaría bien hasta este punto, si no fuera por un comentario en Twitter de Jorge Vázquez en el que menciona que el hace algo parecido con otras herramientas y además le aplica Reconocimiento óptico de caracteres (OCR ).
Y no me quise quedar atrás. El OCR le agrega una capa de texto al PDF que facilita las búsquedas. Ahora necesitaba un programa que literalmente leyera todas las hojas del libro que acabo de crear y agregara esa información al archivo PDF.
Me encontré con un programa con el nombre más simpático que puede uno encontrar: ocrmypdf y hace exactamente lo que estaba buscando. Así que después de hacer esto:
ocrmypdf -l spa libro.pdf libro-con-ocr.pdf
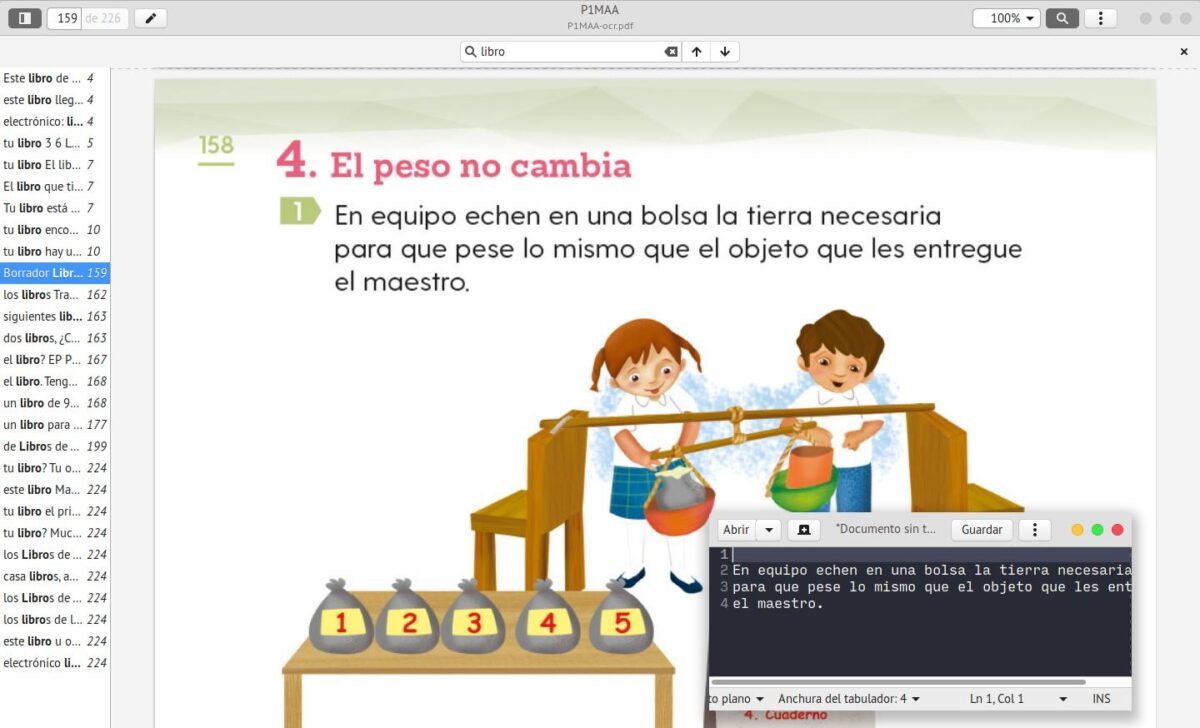
Con el OCR se pueden hacer búsquedas o copiar textos.
Ya tenía un PDF al que le podía hacer búsquedas o seleccionar y copiar textos, claro con algunas imprecisiones ya que el OCR no es perfecto.
México sin libros de texto gratuitos de español y matemáticas.
La eliminación de los libros de texto de matemáticas y español es una medida polémica que ha generado un debate en México.
La medida no ha sido confirmada todavía, porque por alguna razón no se ha compartido oficialmente el contenido de los libros de texto gratuitos.
Ya hay algunas reacciones a base de “filtraciones” de los libros y han sido duramente criticadas por algunos especialistas, quienes consideran que la eliminación de estos libros afectará la calidad de la educación en el país.
Por ejemplo, los invito a que lean La supresión del libro de matemáticas para el primer año de primaria del Dr. Raúl Rojas, un conocedor del tema.
La SEP, por su parte, argumenta que la eliminación de los libros de texto es necesaria para mejorar la calidad de la educación en México, aunque dicho sea de paso desconozco sus argumentos y la mayor discusión se dará cuando los libros sean revisados por los padres, especialistas y el público en general.
Mi impresión es que quieren “desaparecer” los resultados de la prueba PISA y de pasada empezar con “adoctrinamiento” social.
Claro que siempre se puede recurrir a la versión anterior de los libros de español y matemáticas.
Como una medida de precaución descargué ambos libros de primer grado de la página oficial y los dejo aquí en formato PDF para su consulta.


Conclusiones.
El mismo procedimiento se puede aplicar a todos los libros de texto (o eso espero) o a cualquier libro con una presentación similar.
Espero que esta información para descargar libros de texto gratuitos les sea de utilidad, se que es algo técnico pero a lo mejor sirve de inspiración para algo más elaborado.
¡Bendita nueva normalidad!